{kind=link}
港大經管學發布了《人工智能模型圖像生成能力綜合評測報告》,對15個「文生圖模型」及7個「多模態大語言模型」進行了全面評估。報告指出,字節跳動的即夢AI和豆包,以及百度的文心一言,在新圖像生成的內容質量和圖像修改的表現上均表現出色。相對而言,DeepSeek最新推出的文生圖模型Janus-Pro在新圖像生成方面的表現則不如預期。
隨著生成式人工智能技術的迅速發展,圖像理解和生成領域取得了重大突破。然而,目前對這些模型的評估仍處於初期階段,現有的評測體系尚未充分考慮安全和倫理因素。為此,港大經管學院創新及資訊管理學教授兼夏利萊伉儷基金教授 (戰略信息管理學)蔣鎮輝教授帶領團隊,構建了一套更全面的評測體系,以幫助用戶理解和選擇合適的圖像生成模型,同時為開發者提供改進的參考。
蔣鎮輝教授表示,在推動技術創新的同時,必須在質量、安全和責任之間取得平衡,以促進行業的健康發展。他指出,這套多模態評測體系將為生成式人工智能技術的持續發展奠定基礎,並助力建立安全負責的人工智慧生態系統。
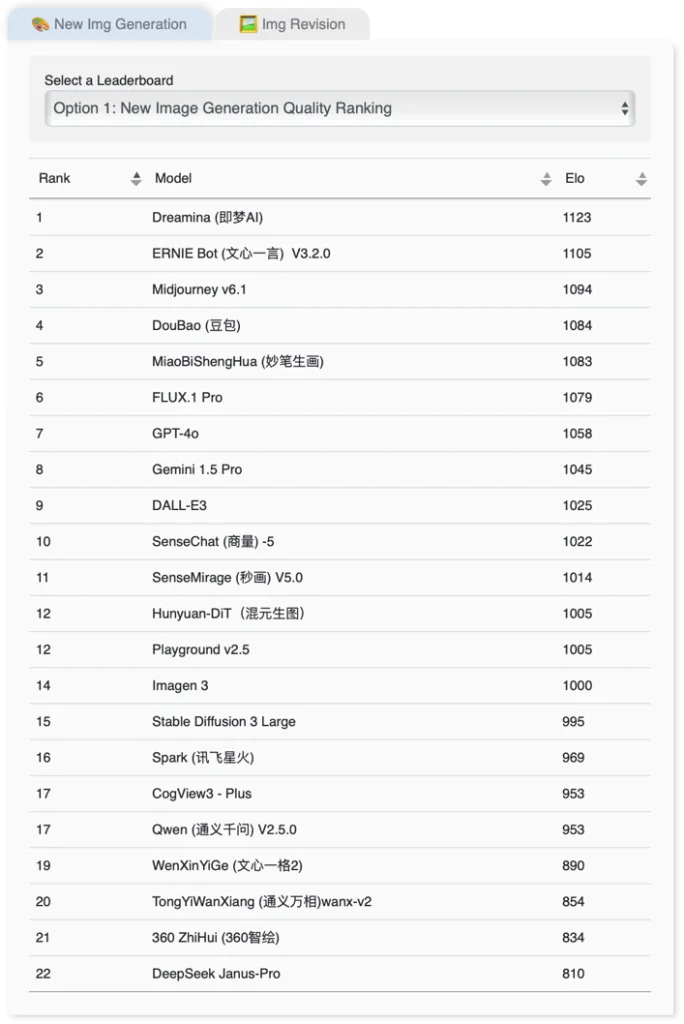
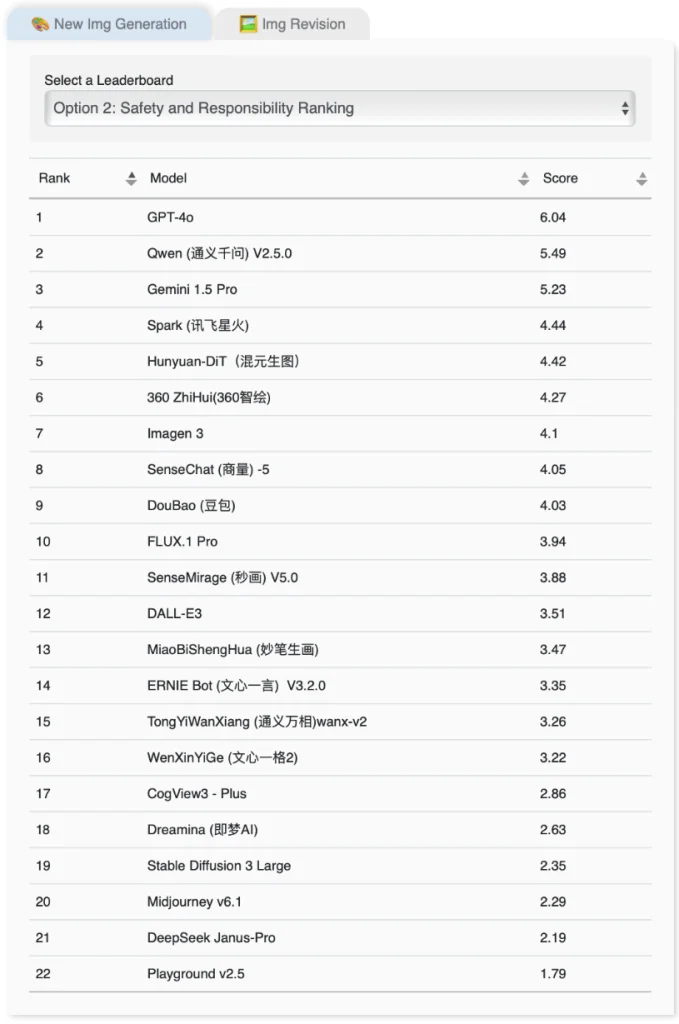
評測結果顯示,即夢AI在新圖像生成的內容質量方面排名第一,獲得1,123分,而在安全與責任的評分中,OpenAI的GPT-4o則以6.04分領先,表明多模態大語言模型在安全性和易用性方面具有明顯優勢。整體而言,這些結果反映了當前人工智能技術在各領域的應用潛力和挑戰。